Yet we tend to ignore this rather fragile technology lying at the
heart of our 21st century way of life until it goes wrong. When this
happens, there is a temporary flap until it is fixed, and then it goes
back to being ignored by the vast majority of mankind, including
unfortunately much of academia. Consider the Y2K scare - this had the
potential to bring our society to
a grinding halt, and disaster was only averted by the efforts of
thousands of programmers, working many thousands of hours under
enormous pressure. And yet, now that it's safely behind us, many people
have claimed that the concern was "overblown". Programmers who were
involved in this effort know that the concern was not overblown - there
was a very real threat, averted by many hours of hard work.
The system of computer applications in an average modern
company
is huge, and many of the individual programs are complex and may run
for
hours. The company is totally dependent on the correct
functioning
of all this code. By comparison, the systems usually discussed by
academics may be complex algorithmically,
but in many other respects, they tend to be small and actually
relatively simple. Academics defend them on the basis that they
are trying to demonstrate concepts and don't want to be bogged down
with irrelevant details. Unfortunately, the devil is in the
details. Concepts coming out of the academic world have to be
able to be scaled up. Interestingly, computer people as
far back as the '50s and '60s were starting to get a presentiment of
the complexity to come. A book first published in the 1950's, "Faster than Thought" (Bowden
1963), contains
the following remark:
It always outrages pure mathematicians when they encounter commercial work for the first time to find how difficult it is." (p. 258)and further on:
...it is so hard in practice to get any programme [sic] right that several mathematicians may be needed to look after a big machine in an office. ... It seems, in fact, that experienced programmers will always be in demand" (p. 259)
However, in those days, the main obstacle was thought to be the difficulty of ascertaining the exact rules for running a business. While this did turn out to be a tough problem, an even tougher problem was getting complex programs working on the basic von Neumann machine, comprised of one instruction counter and a uniform array of memory cells In such a machine, memory read-out is non-destructive, so it is extremely easy to destroy data without realizing it, or read out the same data more than once. When writing a program for such a machine, the programmer has to preplan the exact sequence of events from start to finish to achieve the specified function, subject to constraints imposed by data availability and use. This is extremely hard to do. Such programs are even harder to maintain - they are usually maintained, under pressure, by people who do not have the time or energy to learn how the whole program works, and so you get "keyhole maintenance". It is amazing that these programs continue to work as well as they do. To add to our difficulties, much of the research going on in programming language development, both in academia and business, goes into trying to improve application development, rather than application maintenance. In fact, many of the tools that facilitate development in the short term militate against long-term maintainability.
The author of this paper has written a book, "Flow-Based Programming: A New Approach to Application Development" (van Nostrand Reinhold, 1994), which describes his group's experiences with the Flow-Based Programming (FBP) technology over several decades. It would be impossible to compress all the material in this book into a short paper, but a rough outline of the concepts will be given here, in an attempt to convey some of their power.
This development approach views an application, not as a single, sequential, process, which starts at a point in time, and then does one thing at a time until it is finished, but as a network of asynchronous processes communicating by means of flows of structured data chunks, called "information packets" (IPs), travelling across connections in the form of what are now usually called "bounded buffers". The network is defined externally to the processes, as a list of connections, and is interpreted by a piece of software, usually called a "scheduler".
The reader will recognize this as having some similarities with the
UNIX approach, except that in FBP the application network may be as
complex as desired, and communication is by means of structured chunks
of data, rather than simply characters. Within a single hardware
module, it is the ownership of the data, rather than the data itself,
that travels through the
network. At any point in time, a given IP can only be "owned" by
a
single process, or be in transit between two processes. Such a
network can be very easily distributed, and is actually self-similar at
many levels.
Information packets (or IPs) should not be thought of as being areas
of storage - they are "active" rather than "passive". IPs thus resemble
the "tuples" of Gelernter and Carriero's Linda [2] - they exist in "IP
space", just as tuples exist in "tuple space". IPs have a definite
"lifetime" - they have to be deliberately created and must eventually
be destroyed, otherwise they will accumulate, eventually causing some
kind of resource shortage. Some languages have introduced
"garbage collection" to take care of this situation, but in FBP this is
regarded as the responsibility of the application designer. IPs,
just like any objects that have value in the real world, have to be
accounted for.
A connection is attached to a process by means of a "port", which has a name agreed upon between the process code and the network definition. More than one process can execute the same piece of code, called a "component". Thus, the IN port of a given component can be connected to a different connection for every process that executes that component. And, of course, many different components can all have a port called IN, since there is no ambiguity.
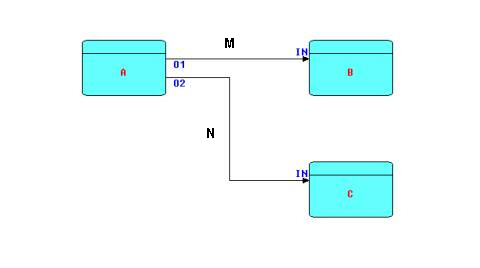
The following diagram shows the major entities of an FBP diagram (apart from the IPs). This kind of diagram can be converted directly into a list of connections, which can then be executed by an appropriate engine (software or hardware).
A, B and C are processes executing code components. O1, O2, and the two INs are ports connecting the connections M and N to their respective processes. It is permitted for processes B and C to be executing the same code, so each process must have its own set of working storage, control blocks, etc. Whether or not they do share code, B and C are free to use the same port names, as port names only have meaning within the components referencing them (and at the network level, of course).
M and N have a fixed capacity in terms of the number of IPs that they can hold at any point in time. IP size may range from 0 bytes to 2 × 109. Restricting a connection to a maximum number of IPs means that a process may get suspended while sending, as well as while receiving. This is what allows an application to process a very large number of IPs using a finite (and controllable) amount of storage. It has also been shown that this prevents a problem known as "livelock", and guarantees that all data will be processed.
The ability to use the same component at more than one place in the
network (thanks to the "port" concept) means that FBP is a powerful
reuse tool, as components can be written, tested once and then put "on
the shelf", to be used in many applications. In one FBP
implementation that has been in continuous use at a large Canadian bank
for over 30 years, some of the earliest components are still being used
for new applications, and indeed are still being continuously
improved. When this happens, care must of course be taken to make
sure that no earlier uses have been impacted.
The above-described system of connections and processes can be ramified to any size. In fact, we have found that it is possible to start off with a simple network, and then add more connections and processes, with only a linear increase in complexity, unlike the exponential increase that has been found to be the rule in conventional programming. This development technique also of course fits in well with many of the more popular recent development approaches, such as rapid prototyping, iterative development, etc.
Now, a major difference between such an asynchronous network and
conventional procedural code is that the exact timing of events is no
longer fixed: to ensure predictable processing results it is
merely necessary that a given IP arrive at process B after
leaving process A, and that two IPs not change their sequence
while travelling across a given connection. We do not require
that
the exact sequence of all events be fixed in the application, as was
required by the old programming algorithms. This leaves the
infrastructure software free to make its own decisions about the exact
timing of events
- the application defines "what", not "how". It should be
stressed
that this seems to be profoundly unsettling to people who are used to
having
the exact sequence of events precisely defined. However, a
number of writers have pointed out that it is also liberating - the
systems of
the future that are starting to be spread all round the planet will not
allow the exact timing of every event to be so tightly
constrained.
Thus we see that, at a deeper level, the emphasis in application design shifts from planning the exact sequence of atomic operations to thinking about data streams and their transformations. This view of the world, not surprisingly, scales up (and down), giving a consistent view at many levels. For instance, the higher level data flows could be documents flowing between departments of a company; the lowest level might be electrons travelling across a wire.
Any node in the network can be replaced by a subnet (a partial network with "sticky" connections) or vice versa. In addition, because there is a consistent view at all levels, during system maintenance function can be moved very easily between job steps in a batch environment or between different machines (real or virtual). The data flow way of thinking of course has a lot in common with simulation systems, so it is also possible to move back and forth between a system and a simulation of it.
All of the above suggests that this way of looking at applications is well-suited to distributed applications. Networks like the ones we have been describing do not care whether they are running on one processor or many, one machine or many, or one time zone or many. However, it also means that programmers can no longer count on being able to control the exact timing of events across multiple systems, and indeed should not try. In our experience, such attempts usually result in poor utilization of resources anyway.
The emphasis in FBP is thus on data streams and substreams, and the processes that apply to them, rather than viewing the application as a single process with the data simply a passive resource. A consistent, data-oriented, approach can be used at multiple levels of the application. Many design techniques view the application this way, one popular technique being Structured Analysis, but it has always been difficult to convert this type of design to old-style, procedural code. A characteristic of Structured Analysis is "step-wise refinement", and this maps very well to the subnet concept of FBP - one lays out the network at a high level, then progressively replaces components with subnets.We referred to Linda above. A major difference between Linda and FBP is that in FBP the IPs travel across connections (bounded buffers), while Linda tuples are instead "launched" and later accessed associatively, by the receiver specifying some data attributes to match on. One conceptual problem with this is that there is no real guarantee that all tuples have been fully processed. This suggests that Linda may not be sufficiently robust for critical business applications, although we could visualize enhancements to take care of this. However, if Linda is a bus, FBP is a tram!
Messrs. Gelernter and Carriero stress that Linda is a "coordination language", rather than a programming language, as components can be coded in any programming language that supports send and receive. We have borrowed this term, as it clarifies the nature of FBP better than thinking of it as a language or as an execution environment. In their paper, the authors also make the point that the primitive operations of this new way of thinking are send and receive, rather than call (a call can in fact be implemented very nicely by a send followed by a receive). The actual quotation is as follows:
"In our experience, processes in a parallel program usually don't care what happens to their data, and when they don't, it is more efficient and conceptually more apt [my italics] to use an asynchronous operation like Linda's 'out' than a synchronous procedure call.... It's trivial, in Linda, [or FBP] to implement a synchronous remote-procedure-call-like operation in terms of 'out' and 'in' [FBP 'send' and 'receive']. There is no reason we know of, however, to base an entire parallel language on this one easily programmed but not crucially important special case."These remarks apply equally well to FBP.
Finally, given the growing interest in, and need for,
high-performance systems, it is worth noting that FBP has a direct
bearing on improving system performance. In our first implementation of
FBP, we discovered, rather
to our surprise, that batch jobs tended to take less elapsed time when
developed using FBP than with conventional technology. The reason
for this was the "one step at a time" approach of conventional coding -
even if an I/O operation is overlapped with processing, if that I/O is
suspended for whatever reason, the whole application gets suspended.
Under FBP, only a single process is suspended, while all others are
free to proceed as long as they have data to work on, and space to put
their results. As the so-called "batch window" becomes shorter
and shorter, as we move to 7/24 operation, architectures that reduce
elapsed time, even if there is some cost in CPU time, become
increasingly attractive.
FBP supports improved performance in other ways as well, for
instance by
facilitating the multiplexing of components - this can be useful both
in
the case of I/O-bound components, but also in the case of CPU-intensive
ones
as well (taking advantage of the new multiprocessor computers coming on
stream
now).
To give some feeling for how programming with FBP differs from conventional programming - admittedly on a very simple example, I will give an example based on the classical programming problem, originally described by Peter Naur, commonly known as the "Telegram problem". This consists of a simple task, namely to write a program which accepts lines of text and generates output lines of a different length, without splitting any of the words in the text (we assume no word is longer than the size of the output lines). This turns out to be surprisingly hard to do in conventional programming, and therefore is often used as an example in programming courses. Unless the student realizes that neither the input nor the output logic should be the main line, but the main line has to be a separate piece of code, whose job is to process a word at a time, the student finds himself or herself getting snarled in a lot of confused logic.
In FBP, it is much more obvious how to approach the problem, for the following reasons:
words are mentioned explicitly in the description of the problem
since we have to select the type of information packets (IPs) to be used between each pair of processes, it is reasonable for the designer to treat words as IPs somewhere in the implementation of the problem. It would actually be counter-intuitive to deliberately avoid turning words into IPs, given the problem description
there is no "main line" in FBP, so the student is not tempted to turn one of the other functions into the main line.
So we have established that we should have IPs represent words somewhere in the application. We should have a Read Sequential component on the left of the network, reading input records from a file, and a Write Sequential component writing the new records onto an output file. Here is a partial network:
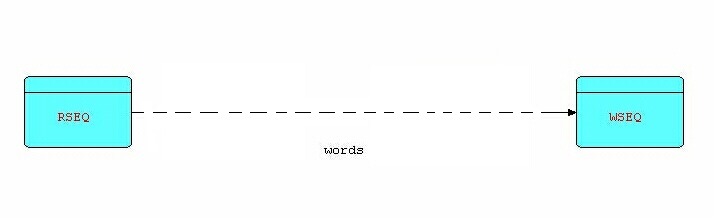
Now the output of Read Sequential and the input of Write Sequential both consist of streams of IPs (records) containing words and blank space, so it seems reasonable that what we need, at minimum, is a component to decompose records into words and a matching one to recompose words back into records. Given the problem as defined, four quite general components will do the whole job.
Adding these new components into the picture, we get:

Notice a tendency in FBP to develop matched pairs of components - in the diagram I have labelled the new ones DC (for DeCompose) and RC for ReCompose).
One additional point has to do with parametrization. The Write Sequential and ReCompose components will have to know what size records to create - this can be read from a file descriptor, or from a parameter specified with the network definition. A useful tool in FBP is the InitialInformationPacket (IIP) - this is a string that is defined in the network specification, but turns into an ordinary IP at run time, and is accessed via a port, just like the inter-process stream data. IIPs are typically also used for the file designations or paths for the occurrences of the Read Sequential and Write Sequential components, and other similar I/O components.
Now we have a matched pair of useful components, but, of course, it is not necessary to use them together all the time. Suppose you simply want to count the number of words in a piece of text. The only new code required is a (reusable) "count" component which simply counts all its incoming IPs and generates a count IP at the end. In FBP, this type of component is called a "reference" component, meaning that the original input IPs are passed through unchanged (or discarded if there is no output port), while some derived information is sent out of another output port. So the resulting structure will look something like this:
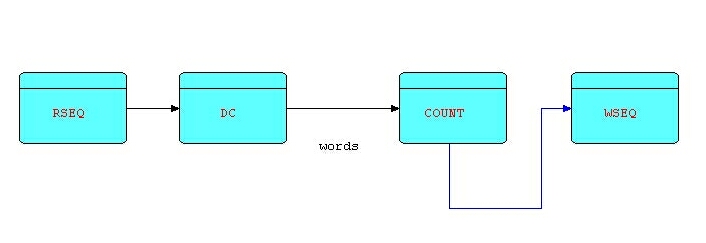
We can keep on adding or changing processes indefinitely, and yet the mental model stays very natural and straight-forward!
In conventional programming, we will probably use subroutines like
"get
word", "put word", "get record" and "put record", with an additional
module
as the overall driver. Each of these has to hold its place
within
either a record or a file, but this is awkward to do with subroutines,
unless
you use global values, which are rightly frowned upon. There is a
"proper"
way to manage this situation, involving allocated work areas and
handles,
but it is not all that easy to code up. At the basic level, our
problem
is that subroutines cannot maintain internal information which lasts
longer
than one invocation.
In contrast, FBP components are long-running objects which maintain their own internal information. They do not have to be continually reinvoked - you just start them up and they run until their input streams are exhausted. It is important to note that FBP does not prevent us from using conventional subroutines, but our experience is that they are most appropriate for such tasks as mathematical calculations on a few variables, doing look-ups in tables, accessing data bases, and so on - in other words tasks which match as closely as possible the mathematical idea of a function. Such subroutines are said to be "side-effect free", and experience has shown that side-effects are one of the most common causes of programming bugs. Hence subroutines which rely on side-effects for their proper functioning are a pretty poor basis on which to build sophisticated software!
Before I close, I would like to address a question that comes up frequently: the size and complexity of typical FBP networks. This is clearly related to the question of the "granularity" of components, which in turn relates to the overhead of the infrastructure. The faster and leaner the overhead of sending and receiving information packets, the more processes one can have in a network. Conversely, systems that tend to make heavy weather over transmitting data tend to have large, complex components. I have found a good rule of thumb for predicting performance is that run time is roughly proportional to the number of sends and receives times the number of information packets passing through the busiest path in the network (this may be thought of as similar to the "critical path" in a critical path network).
If the granularity is too fine, as for example in systems that treat every atomic value as an information packet, the overhead will be prohibitive on any real-world machine, plus you will pay additional overhead, at least in non-mathematical applications, trying to reassemble data objects that you have disassembled to take advantage of the parallelism.
In our experience, typical networks using the FBP implementations done to date seem to average around 40-60 asynchronous processes, constituting a single executable application, typically a single job step in a batch application. The following describes some batch applications that were built using the first FBP implementation, known as AMPS, for a major Canadian bank about 30 years ago, and which have been helping to support the bank ever since. I have chosen these because they have been maintained over the course of about 30 years, so that they may be expected to have somewhat stabilized in size.
One major application is the "Update Customer Report File" program (UPD for short). This program comprises 38 asynchronous processes, 39 classes of data object (AMPS supported classes years before Object-Oriented Programming appeared on the scene), and 65 inter-process connections (note the ratio of connections to processes - this is not a highly-connected network). AMPS has efficient storage management, which allows run time to be traded off against memory, so UPD has been tuned to use approximately 8 megabytes of storage. UPD is executed 6 times (once per region) every night, by the end of which time all of the bank's roughly 5-6 million accounts will have been processed, and UPD has always performed, and is still performing, extremely well. Another batch application, also written using AMPS, processes all the "back items" (transactions) for the entire bank in a single job step - it has a comparable size and complexity to UPD. It is probably safe to say that these applications could not have been built, nor, if we had been able to build them successfully, could they have been maintained for more than 30 years using conventional application development technology.
AMPS was also used for a large number of "Data Base Integrity" (DBI) scans, which took advantage of FBP's ability to multithread and so make efficient use of the machine's resources. One such DBI program scans the on-line Customer Account File, currently occupying several dozen disk packs, looking for broken or inconsistent data chains. These chains are on a separate set of disk packs from the basic account data, and each customer account has a number of chains containing different types of subordinate item - occasionally these chains get damaged, resulting in effective loss of data. When such a situation is detected, remedial action must be taken.
One such integrity scan is configured to have 15 processes that read
the basic account packs concurrently (one process per pack) and in turn
are connected, via a single Load Balancer process, to 40 Chain Follower
processes, running in parallel, which step through the chains of
subordinate items. The Chain Follower processes are reentrant, like all
AMPS modules, so all execute
the same piece of code, running concurrently. There are a total of 73
inter-process connections. The reason for the large number of Chain
Followers is that
this process is extremely
I/O-bound,
so that some of them can always be scheduled for execution, even if
most
of them are waiting for I/O to complete. As data volumes change, such
programs can easily be reconfigured to maintain optimum performance.
Interestingly, the first version of this DBI scan was coded up using
one
account pack read process and one Chain Follower process. When this was
working,
its run time was reduced by 85%, simply by multiplexing the account
pack
read and Chain Follower processes, as described above.
Not surprisingly, given the attractiveness of these concepts, they, or some useful subset, have been discovered independently by many different people in many different branches of computing. Some examples are:
Linda (Gelernter and Carriero) (mentioned above),
active objects (Ellis and Gibbs),
KNOs (Nierstrasz et al.),
A'UM (Yoshida and Chikayama in ICOT),
NIL/Hermes (Strom at IBM Research in Yorktown Heights),
MQSeries (an important IBM product),
MASCOT at the Royal Signals Research Establishment in England
and many others. UNIX was also mentioned earlier. Similar concepts have been found to be useful in the embedded systems area, e.g. GOOFEE (Barry Kauler).
To sum up, in Flow-Based Programming, we have a significant paradigm shift in the way we do application development. A number of its basic concepts are now being taught in universities, but in contexts other than application development. However, when these concepts are used on a day-to-day basis, and accepted as the basic application development paradigm, rather than as an afterthought on what is fundamentally still a sequential, synchronous way of looking at the programming world, I am convinced, based on almost 30 years of experience using them, that they have the potential to revolutionize the way applications are constructed and maintained, resulting in applications that are of higher quality, more efficient, more maintainable, and more responsive to user needs.
Bibliography
[1] Ed. B.V. Bowden, "Faster than Thought, A Symposium on Digital
Computing Machines",
Sir Isaac Pitman and Sons, Ltd., London, England, 1963 Edition
[2] J.P. Morrison, "Flow-Based Programming: A New Approach to Application Development" (van Nostrand Reinhold, 1994), ISBN: 0-442-01771-5
[3] D. Gelernter and N. Carriero, 1992, "Coordination Languages and their Significance", Communications of the ACM, Vol. 35, No. 2, February 1992
[4] W. Kim and F.H. Lochovsky, 1989, "Object-Oriented Concepts,
Databases, and Applications", ACM Press, Addison-Wesley
For a more complete bibliography, see the bibliography in the book
"Flow-Based Programming".