This chapter has been excerpted from the book "Flow-Based Programming: A New Approach to Application Development" (van Nostrand Reinhold, 1994), by J.Paul Morrison. A second edition (2010) is now available from CreateSpace eStore and Amazon.com. The 2nd edition is also available in e-book format from Kindle (Kindle format) and Lulu (epub format). To find out more about FBP, click on FBP.
For definitions of FBP terms, see Glossary.
|
Material from book starts here:
Object-Oriented Programming (abbreviated in what follows to OOP) has captured the imagination of a sizable, and influential, segment of the computer world, and understandably so, since it promises solutions to many of the problems which confront our industry. Not only does it have proven successes in the area of user interfaces, but it offers the very inviting prospect of libraries of reusable programming components which can be bought and sold on the open market. On the other hand, its very success has resulted in its being broadened until the term OOP now covers a wide spectrum of different technologies with a few basic concepts in common. The literature on the subject is confusing to the uninitiated, and the more one reads about the subject, the more different variations one encounters, all rallying behind the Object-Oriented banner. Given all the excitement, I have spent some time trying to understand what is being offered and what it can do for us. This chapter is the result of this work, and I hope that some readers will find it helpful. Naturally, one of the effects of the diversity of different views about what OOP is is that almost any comment I may make about it can be countered by someone who has a different view, but I base these observations mostly on the most widespread dialects of OOP, so I believe they have some validity.
Before I go any further, I would like to say that I believe FBP shares many characteristics with OOP, but at this point in time I hesitate to call it object-oriented, as there are certain fundamental differences of approach. However, after reading this chapter, some of my readers may conclude that any differences are basically surface differences, and that FBP is an object-oriented technology. Interestingly, Rob Strom, who developed NIL (Strom and Yemini 1983), described in the next chapter, which has strong similarities with FBP, tells me that initially his group thought it important to disassociate themselves from OOP, but recently they have come to feel that OOP is now so broad and there are so many similarities between NIL and OOP that they are now actively working with the OO community.
OOP is also another perfect example of the gap between business and academia that I talked about earlier: a lot of the interesting research work on OOP is hard to apply to business needs, while business badly needs technologies which can ease the burden of developing and maintaining application code. When academics start using payroll applications for their examples, rather than rotating squares and rectangles, we will know that we have turned a corner!
It is generally accepted that the first OOP system was Smalltalk, from Xerox PARC, although some writers identify Simula as the first OO language. It seems that many people today still consider Smalltalk the archetypal OOP language, although it is many ways a "small" implementation of the concepts, by which I mean that it is great for exploring a number of the OOP concepts, but it is not clear that its concepts scale up to large-scale business applications. I have worked with Digitalk's Smalltalk V/PM, so most of my examples will be drawn from that system. C++ is a different, and in some ways more pragmatic, approach to implementing object-oriented concepts, which is gaining increased acceptance, but, since it is a hybrid between OO concepts and a conventional HLL, its users have to contend with a more complex mental model. A different approach to hybridizing a HLL with OO concepts is Brad Cox's Objective-C (1987), which is not as well known as the other two, but also has a number of interesting concepts. All of these languages are basically control-flow oriented, and therefore suffer from the problems we have described in previous chapters. A number of workers in the OO field are starting to recognize this, and I will be describing some of their work later in the chapter.
To lay a foundation for discussing the differences and similarities between FBP and OOP, we need to talk about a few of the basic concepts of OOP for those not familiar with its concepts. The basis of Smalltalk and all OOP systems is the "object", which can be described as a semi-autonomous unit comprising both information and behaviour. OOP objects are usually selected to reflect objects in the real world, and this relationship is a major source of the appeal of OOP to application developers. As I mentioned above, it is also a characteristic of simulation languages, and also of IPs (Information Packets) in FBP. Of course, since real world objects vary widely in size and complexity, it becomes far from trivial to decide what the objects in your universe of discourse are going to be. Just as it is in conventional programming, it is extremely important to do a good job of modelling your data before you start an OO design. The approach of Object-Oriented Analysis is somewhat different from that of conventional data modelling, but many workers in the field claim that proper modelling is even more important with OO as an error at this stage can adversely affect your whole design. This is also true of course for FBP.
One very powerful but non-obvious similarity between FBP and Smalltalk is that they both use "handles" to refer to objects (except in the case of Smalltalk integers). When I request a new instance of a class in Smalltalk, I get a set of instance variables "out there", and a handle to let me refer to it, just as we have seen happens when we create a new IP in FBP. We can then do things with this object handle, e.g. send messages to it or use it as a parameter in a message to another object. Smalltalk also looks after "garbage collection" of the object if its handle is no longer in use - this function could easily be added to FBP, but as I said earlier we're not sure whether it's desirable.
These object handles are what allows objects to talk to each other. Once we have selected classes of objects which will represent the real world objects of interest to our application, the next requirement is that these objects be able to communicate - in short, that their behaviour be cooperative. For this function, Smalltalk uses the expressive metaphor of "message sending": Smalltalk objects are said to send messages to each other, resulting in activity on the part of the receiver, which may in turn send messages on to other objects. This also is a good fit with how we think of the real world. Unfortunately, this Smalltalk terminology is misleading if it suggests any kind of asynchronous message flow, as Smalltalk's "message sending" is purely synchronous: the sender has to wait until the receiver comes back with a reply. In today's terminology of parallel processes, the sender is "blocked" until the reply is received. This mechanism is essentially equivalent to a subroutine call, and this is in fact how it is implemented (with a subtle difference which we will discuss in the next paragraph). Smalltalk does support asynchronism by means of its fork and semaphore facilities, but the basic paradigm is synchronous and, as we have seen above, this restricts the developer in certain fundamental ways. In C++ (and also sometimes in Smalltalk) this is referred to as "method invocation", which is a more accurate description of what is really going on.
Method invocation is essentially an indirect subroutine call. The caller specifies an operation, and it is the class to which the receiver belongs which determines the actual piece of code which is executed. In both Smalltalk and C++, each such piece of code (called a "method") is part of a class and its address is not directly known to its caller. The caller specifies the function desired by naming an object (or the class itself) and the desired function, e.g. it might tell an object of class "rectangle" "rotate 90 degrees". The underlying software then uses the class information of the object to locate the actual code which is to be executed.
Although this seems very straight-forward in the classical OO examples, in practice I found it really frustrating to me as a user, because it is inherently asymmetrical. Many of these requests involve more than one object, so you have to pick one as a receiver, and pass the others (or their handles) as parameters. This means that I, as the user, was never quite sure which object should be the receiver, and sometimes a series of similar functions would flip back and forth bewilderingly. For example, when displaying a series of data objects, I had to use several different messages, some of which were sent to the medium object with the data object as parameter, and some of which were the other way around. Another example: because of this problem, Smalltalk has problems with such simple commutative operations as + and *. Smalltalk V/PM has actually implemented a facility where, if an operation fails, the system reverses it and tries again. This function is only available to primitive operations, and is not even used there consistently. You also have to be careful not to write methods which go into a closed loop! Although some OO dialects, like CLOS, select the method based on the classes of more than one participating object, I would expect that allowing method selection to be based on several classes not only would result in even larger numbers of methods, but could result in significant management problems.
The indirect call characteristic of OOP systems does provide a degree of configurability, since it is true that the caller does not have to know the name of the subroutine which will actually be executed. In addition, since different classes can support the same function identifier (sometimes called the "selector") in different ways, you get an additional useful characteristic sometimes called "genericity", which some writers consider the basic characteristic of OOP systems (many others don't, though). However, the requester of a function does have to be able to locate the object that it wants to send the message to and also has to specify the name of the desired function, e.g. "print" or "rotate", so we still have a configurability problem, once removed, unless the process of identifying the recipient object can be completely externalized from the requester's code. Remember, to achieve full configurability we need to be able to hook together components into different patterns without modifying them in any way, which also means having an independent specification of how things are connected. This can only be done today by having "high-level" methods which specify how things are hooked together. I find it interesting that, in most of the literature, the orientation of Smalltalk is very much towards building new classes, rather than towards reuse. Applications are developed mainly by cloning old methods, with its attendant problems, rather than by using black box code. The very idea of allowing a developer to modify the behaviour of an existing class, even if only for his or her own purposes, runs counter to the reuse concepts described earlier in this book.
Two last comments about genericity: my (limited) experience is that application developers don't use it very much, and its main triumphs seem to be in the GUI area. When asked to give examples of genericity, writers on OO always seem to pick "display" and "destroy". It may be that, in business, you don't often use the same messages for different classes. For instance, at the numeric value level, subtracting a number of days from a date is quite different from subtracting a date from another date, or a date from days (you can't), so the user has to be very aware of the types of the operands. To me this means that it doesn't buy you much to be able to call them all "-". In fact, in Smalltalk you often see message names like "subtractDaysFromDate", to tell the user what types the message expects (there is no type checking at compile time, so this is particularly important). Now, if you don't make much use of genericity, all you have left is the indirect call mechanism, which should be part of any programmer's toolkit anyway!
The following three attributes seem to be present in all OOP systems to a greater or lesser extent, but they are given different weights by different writers: genericity, encapsulation and inheritance. We have already talked about genericity in OOP. Genericity is also implicit in FBP as the same IP can be sent to different processes to achieve different results (and usually is), or components can be designed to accept a narrower or wider range of possible input formats as determined by reuse considerations. For instance, a Collate could accept only two input streams, or 'n' input streams. It could accept just one input IP format, or many, determined by descriptors as we described above.
Inheritance is claimed by some to be the major characteristic of OOP, and it is certainly an important concept, but my personal view and that of other people I have talked to is that its use should not be pushed to extremes. As long as inheritance is used to reflect the fact that things in real life can usually be grouped into classes which are subsets and supersets of other classes, it works quite well, and would in fact fit in quite well with the IP type concept that is implemented by descriptors in FBP. For instance, a file might contain records representing vehicles, which you would then "specialize" into Volkswagens, Pontiacs, etc., based on a code within the common part of the records. Some processing would then be valid for all vehicles, other processing just for Pontiacs. If a message cannot be answered by a Pontiac, it is passed up to the "vehicle" level. Generally, as you move down the class hierarchy, you add more attributes - so start off with the set of attributes common to all vehicles. When you discover that a file record represents a Pontiac, you now know how to read the remaining attributes. This concept could in fact be added quite naturally to the descriptor mechanism of FBP.
The major difficulty with classification, however, is that, as soon as you try to become more analytical about what a class really is, things start to get more confusing. What seems clean and intuitive when applied to oak and fir trees becomes less clear when you look at it more closely. In fact, the OO concept of "class" seems to involve several different concepts which are combined in different combinations in different OO implementations. For those interested in this topic, there is an interesting recent article by W. Lalonde and J. Pugh (1991) which attempts to separate out the different ideas underlying the idea of "class". To give you some flavour of this debate, consider the difference between a square and a rectangle from an OO point of view. There was a recent interesting exchange of letters on this topic in Communications of the ACM, triggered by a letter from J. Winkler in the Aug '92 issue: in a hierarchy of geometrical shapes, a square is usually defined as a rectangle with all four sides equal. From one point of view, it is therefore a subclass of rectangle. However, subclasses usually have more instance variables (attributes) than their superclasses, while a square can be completely specified using only one measurement, instead of two. As if that weren't bad enough, OO rectangles can accept messages asking them to change individual dimensions, e.g. "set height to:". If you change a rectangle's height to be the same as its width, does it change to being a square, or must you create a new intermediate class - that of "square rectangles"? The point is that this is an example of specialization by the addition of constraints. There needs to be some general mechanism to specify constraints on objects, and we also have to decide whether to use the constraint, e.g. by allowing one dimension to change the other, or just use it to detect errors on the part of the client, e.g. "violates constraint - please check dimensions". The heading on Winkler's letter is "Objectivism: 'Class' Considered Harmful" (Winkler 1992)!
While human beings naturally try to classify the world to make it easier to grasp, the real world may resist being so classified. As a non-zoologist, I had imagined that all mammals had been neatly categorized long ago, so I was amused recently to run into this description of the difficulty zoologists encounter in trying to classify the hyrax (Krishtalka 1989): "They resemble a cross between a rhinoceros and a rodent. ...the hind limbs have three toes (rhinos), one of which ends in a long claw (rodents), the other two in hooflike nails (rhinos)...." The list goes on for a bit, then Krishtalka writes: "Such a smorgasbord of physical traits earned a dyspeptic taxonomy.... Recent opinion is divided between a horse-rhino-hyrax evolutionary connection and a sea cow-elephant-hyrax linkage." While this kind of confusion can actually be amusing, our tendency to make snap classifications and then act as if they were the whole truth may actually be harmful, either to ourselves or to others: while everyone today with a reasonable education knows that whales are mammals, not fish, the old mental association may be what allows officials to refer to "harvesting" whales. We can certainly talk about "harvesting" herring, but we don't talk this way about tigers, cattle, butterflies or people, so why whales? If you are interested in this area of linguistics, you should take a look at the work of the linguist B.L. Whorf (1956), alluded to elsewhere in this book, on how the words we use affect our actions.
As we move into the world of business programming, we run into situations where class hierarchies may seem very natural at first sight, but in fact are really not appropriate. For instance, it might seem natural to assign a bank account object to one of a set of account type classes: SAVING, CHEQUING or COMMERCIAL. This way, a deposit could be sent to an account and automatically cause the right piece of code to be invoked as a method. While this seems quite attractive at first, in fact, at best this would result in a number of very similar methods which would have to be separately managed and maintained. At worst, it could make it very difficult to develop new, hybrid offerings, such as a chequing account which offers daily interest. Banks have found that it is better to make this kind of processing "feature-oriented" - one should decide what are the atomic features of an account, such as interest-bearing or not, bankbook vs. statement, cheques to be returned or not, and then implement them under switch control to produce the various types of account processing. Hendler gives a somewhat similar example (1986), using professions. He points out that while professions are often used as examples of classes, they may not be mutually exclusive - a person might be both a professor and a doctor - so a person may carry attributes which relate to both of these professions. Mixed classes provide a possible solution, but this technique has problems as well. In FBP, the "tree" technique seems a natural way to implement this kind of thing (see Chapter 12, on Trees), as the data associated with each profession can be held in separate IPs attached to the IP for the person.
In spite of what I have said above, I do believe that one of the most important contributions OO has made towards changing the way application design is done is that it has moved data to the foreground. Programmers coming to FBP from conventional programming have to undergo precisely the same paradigm shift: from concentrating on process to concentrating on data. Typically, in FBP, as we have seen in the foregoing chapters, we design the IPs and IP streams first and then decide what processes are needed to convert between the different data streams. In OO you have to decide on the object classes, and then decide what messages each class should be able to respond to.
For many OO enthusiasts it is this concept of "encapsulation" which is the central concept of OO. In fact, this is not a new concept at all (one of Dijkstra's famous remarks was that programs should be "like pearls"), and Parnas wrote one of the seminal articles on encapsulation in the early 70s (Parnas 1972). Encapsulation simply means the idea of having the vulnerable insides of something protected by a protective outer coating, sort of like a soft-centred candy (or a turtle). This is obviously a good design principle, and the reader will notice that FBP components in fact have this characteristic, as they are free to decide what IPs they will accept into themselves, and can do more or less validation of their input data, depending on how reliable their designers judge their data to be. Encapsulation can also be implemented at the network level, by having outer processes protect inner ones, or by inserting transformer processes into the network. This is a better solution than building the validation into every component, as the processing component can just provide the basic function, and the designer can request more or less validation by adding or removing editing processes. In OO, an object is encapsulated together with all of its methods, which involves predicting all the services that an object may ever be requested to perform. This, however, is very hard to do, and may result in a never-ending stream of requests for enhancements as new requirements come up. How can one predict all the functions that, say, steel might be used for? Remember Wayne Stevens' story about an airline attendant using a hearing set to tie back a curtain (recounted elsewhere in the book)!
In FBP, we always encapsulate processes and can also encapsulate IPs if desired - the former occurs automatically as nobody has access to the internals of a process except the supplier: users can only know its inputs, outputs, parametrization and some behavioral aspects, such as what it does when it sees a closed output port. As far as protecting IPs is concerned, a number of techniques are available, as required by the designer, and it is quite possible to have IPs whose structure is never seen by application code. However, FBP does not insist that we predict all the processes that will ever handle a particular IP type. Rather, the emphasis is on deciding which IP types a given process will accept or generate. Instead of having to predict all the uses that steel might be put to, we only have to decide which materials we can build a bridge out of. The latter seems a much more manageable problem!
Because Smalltalk's "message sending" terminology sounds like data flow, it is often thought that OO should be relevant to distributed systems design, but in fact, as Gelernter and Carriero point out in an article analyzing the differences between their Linda (described in the next chapter) and OO (Carriero and Gelernter 1989), it is actually irrelevant to it. In fact, as they say, a truly distributed message passing system has to be built on top of an OO system, just as it does on top of a conventional subroutine-based approach. Here is a quote from a paper by another of the gurus of this area, Barbara Liskov, and her coworkers: "We conclude that the combination of synchronous communication with static process structure imposes complex and indirect solutions, and therefore that it is poorly suited for applications such as distributed programs in which concurrency is important" (Liskov et al. 1986). It is interesting that "basic" FBP occupies the "asynchronous, static" quadrant of Figure 2-1 of this article, while the addition of dynamic subnets moves FBP into the "asynchronous, dynamic" quadrant, which the authors of this article say is unoccupied to the best of their knowledge. Interestingly, they go on to say, "Although such languages may exist, this combination appears to provide an embarassment of riches not needed for expressive power." Our experience, on the contrary, is that adding a dynamic capability to asynchronous communication can be extremely productive!
Most OO implementations are synchronous, so the basic primitive is the indirect call through the class. As I said elsewhere in this book, our experience with FBP tells us that the subroutine call is not the best foundation on which to build business applications. A "call" can in fact be simulated very nicely by issuing an FBP "send" followed by a "receive". This will have the effect of suspending the requester on the "receive" until the downstream process returns an answer, just as a "call" suspends the caller. Gelernter and Carriero make the same point and go still further in the above-mentioned article:
"In our experience, processes in a parallel program usually don't care what happens to their data, and when they don't, it is more efficient and conceptually more apt [my italics] to use an asynchronous operation like Linda's "out" than a synchronous procedure call.... It's trivial, in Linda, [or FBP] to implement a synchronous remote-procedure-call-like operation in terms of "out" and "in" [FBP "send" and "receive"]. There is no reason we know of, however, to base an entire parallel language on this one easily programmed but not crucially important special case."
A call which spans multiple machines is sometimes called Remote Procedure Call (RPC), and a number of the people working on distributed systems have pointed out the inappropriateness (as well as poor performance) of this algorithm when building complex distributed systems. K. Kahn and M. Miller (1988) point out the problems of basing a design for distributed systems on RPC. They also stress the desirability of having a single paradigm which scales up from tightly coordinated processes within a single processor to largely independent cooperating processes, perhaps on different machines.
FBP and Linda (we will talk about Linda in more detail in the next chapter) are fundamentally asynchronous, whereas Smalltalk-style OO is synchronous. The real difference here is that, although the methods of an object are the only routines which can have access to the object's internal data, when these methods are to be executed is determined by other objects, whose methods in turn are driven by other objects, and so on. While such synchronous objects show autonomy of data and behaviour, they do not have autonomy of control. As such, I feel that synchronous OO objects are more similar to FBP IPs than they are to FBP processes. In a Smalltalk (not counting "fork") or C++ application, there is actually only one process. This can lead to counter-intuitive solutions. For example, in a recent book about C++ (Swan 1991), in an example involving a simulation of people using elevators, the class Building (which is really running the whole simulation) apparently has to be treated as a subclass of the class Action. The problem, of course, is that there is only one process, external to all the objects, which is basically "Run the simulation".
If you cast your mind back to the Telegram problem described in Chapter 8 [this is the problem where text is read in from a file and must be written out in records of a different size, without breaking individual words], you will remember that the conventional programming solution required several of the routines to be invoked repeatedly using handles to maintain continuity. This solution maps very nicely onto an OO "collaboration diagram" which changes subroutine calls into "message sends" and "replies" between objects (remember the caveat about what "message sending" actually means). Here is basically Figure 8.10, recast into OO terms (I have created 4 "stream" objects: 2 word streams and 2 I/O streams):
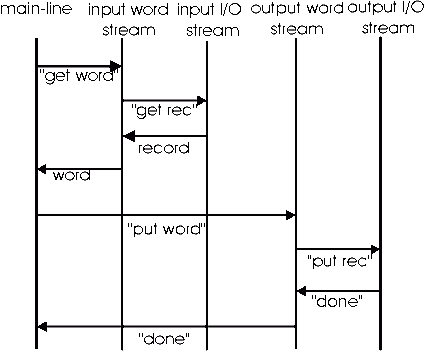
Figure 26.1
While this solves the problem of subroutines which have to maintain continuity between successive invocations (the infrastructure maintains the continuity), this is still a purely synchronous solution. Now let's show an FBP solution to this problem (from Figure 8.2):
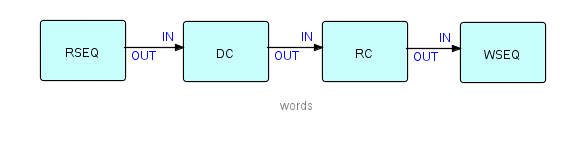
Figure 26.2
[In case you didn't figure it out... in this diagram, RSEQ means "Read Sequential", WSEQ means "Write Sequential", DC is "DeCompose" and RC is "ReCompose".]
Not only is this much easier to grasp intuitively, but it uses reusable components, plus it is very obvious how the function can be extended if the designer ever needs to.
I have tried to show in the earlier chapters that asynchronism is liberating, and I hope I have managed to convey some feeling for its power. In fact, many of the leading thinkers in OO also realize the need to add asynchronism to OO to relax the tight constraints imposed by the von Neumann machine. Many of today's advanced machine designs in fact require these asynchronous design concepts (for a survey, see a recent (1990) article by Gul Agha). Agha uses the term Concurrent OOP (COOP) to describe his approach, which combines the concept of "actors" with OO. Another term you may run into is "active objects", which act, as opposed to "passive objects", which are acted on. In modern user interfaces we already see functions which behave much like active objects, e.g. printers (for printing objects), shredders (for destroying objects), and so on. You just drag and drop the icon (small graphical symbol) of an object, e.g. a file, onto a shredder icon - this is like pressing the start button on a trash compactor. Before it starts, however, the shredder politely asks you if you really want to do this. This is another characteristic of this kind of object: they can independently gather information for themselves. Once the shredder or printer has started, the user is then free to attend to other things.
Another researcher who feels that basic OO has to be broadened by the addition of asynchronism is de Champeaux at Hewlett-Packard. He is looking at the use of a trigger-based model for inter-object communication. Here is a quote from an article about OO research directions [that appeared] in the Communications of the ACM: "This model [where the sender is suspended until the receiver sends the result back] is not rich enough to describe all the causal connections between objects an analyst needs to model." (Wirfs-Brock and Johnson 1990) Interestingly, de Champeaux's work suggests that a richer interaction model than (data-less) triggers is necessary. One of the forms he is looking at is "send-no-wait" (where data and the trigger are simultaneously transmitted). One of the chapters in a recent book (Kim and Lochovsky 1989), is called "Concurrent Object-Oriented Programming Languages", written by C. Tomlinson and M. Scheevel, and provides an excellent survey of this new thinking about ways to combine OO with concurrency. Again, Brad Cox, who is the inventor of Objective-C and one of the acknowledged gurus of OO, has come to feel that OO alone is not adequate for building large systems. He came to the conclusion that FBP concepts should be implemented on top of Objective-C, and then could be used as building blocks for applications. Using a hardware analogy, he refers to Objective-C as "gate-level", and FBP as "chip-level". He had in fact already started experimenting with processes and data flows independently when he found out about our work and contacted me. He has advanced the idea that the time is ripe for a "Software Industrial Revolution", much like the previous Industrial Revolution which has so totally transformed the world we live in over the past couple of centuries. Like Brad, I believe many of the tools for this revolution are already in place, but many writers have remarked on the enormous inertia of the software industry - this has always struck me as ironic, given the incredible rate of change in the rest of the computer industry.
Let us try to show with an example some other differences between synchronous OO and FBP. It is quite hard to find an example which lets one compare the two technologies fairly, as the synchronous orientation of most OO work means that their examples tend to be synchronous as well. However, given that batch programs are not going to go away (in fact, there are good theoretical reasons why they never will), I will use as an example Brad Cox's example of calculating the total weight of a collection of objects in a container: say, pens and pencils in a pencil holder. While being totally procedural, it is an example of the "small batch" logic which is also handled very well by FBP.
The basic design mechanism in this kind of procedure is the collaboration diagram, of which we gave an example above. At any point in time we will have three objects: a requester, a container and an object within it. The interaction is then as follows:
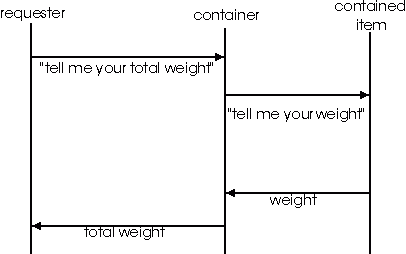
Figure 26.3
I can still remember my feeling of dismay at seeing the right-to-left, returning flows in the above diagram - these mark this diagram as being call logic, rather than flow logic. Every pair of lines represents a client-server relationship - OO people call this "delegation", but it is not delegation as humans practise it. Rather it is like standing over someone, and saying, "Now type this line; now type this line". In fact, client-server relationships make much more sense when the relationship is asynchronous, allowing the client to go about his/her business while the server is doing its thing. Human beings don't see any point in delegating work to others unless it frees them up to do something else. This kind of interaction is also not "cooperative" as FBP understands the word. In FBP all the processes are at the same level - there is no boss. In the above diagram, while there may well be situations where either object can drive the other, one of the objects still has to be the driver (as long as one stays with passive objects only). There is very definitely a boss, and it is the object at the far left.
The logic for the "compute total weight" method of the Container object is a loop which steps through its contained items. It could be described by the following pseudocode:
set total weight to tare weight of self
get first item 'a' in (attached to) self
do as long as get is successful
send message to 'a' to get its weight
add result to total weight
get next item 'a' in (attached to) self
enddo
return total weight
Figure 26.4
This method needs functions to "get first" item and "get next" item within the container. These functions would return an item's handle, plus an indication of whether the request was successful. Once an object has been located, the container can send messages to it.
Although the same general logic can step through a variety of different collection structures (you basically need different method subroutines for each collection type), there is a basic assumption in the above logic, namely that all the items in the collection are available at the same time. As we have seen in previous chapters, this is not really necessary (since only one item is handled at a time), and may not even be possible. In addition, our experience with FBP tells us that this function should really be designed as a reusable component which is usable as is, in object code form, without needing any modification or recompiling. Most programming systems tend to present their ideas from the standpoint of someone writing new code, whereas FBP experience tells us that people don't want to write new code if they can get something off the shelf which does the desired job. Key to this (and also to being able to distribute such systems, now or later) is the requirement to avoid calls - as we pointed out above, the subroutine call mechanism forces tight coupling, whereas we want the data being generated by a procedure to go onwards, not back. The only way I know of to achieve all these goals is to design the function as a stand-alone function which uses ports to communicate with its neighbours. This results in a component with the following shape (you will recognize this as a "reference" type of component):
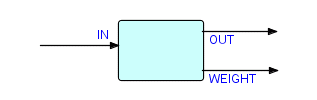
Figure 26.5
This component accepts a stream or multiple substreams of IPs and generates one IP containing the total weight (or one per substream). Since the container has weight (its tare weight), let's provide it as the first IP of the (sub)stream. This diagram is really a fragment of an enhanced collaboration diagram connecting multiple processes with one-way flows instead of a single process talking to itself with two-way flows!
The logic of the above process can be represented by the following pseudocode (which should be familiar from earlier chapters):
create IP to contain total weight
receive from port IN using handle 'a'
set total weight (in weight IP) to (tare) weight of 'a'
send a to port OUT if connected
else drop 'a'
receive from port IN using handle 'a'
do as long as receive is successful
add 'a's weight to total weight
send a to port OUT if connected
else drop 'a'
receive from port IN using handle 'a'
enddo
send weight IP to WEIGHT port
Figure 26.6
Not surprisingly, it has the same general structure as the method pseudocode shown above, but there are certain key differences. The logic shown above can process any data stream for which "a's weight" is defined for each IP in the stream. Incoming IPs are passed on to OUT (if it is connected), and the weight goes in an IP of its own to the port called WEIGHT. Remember Gelernter and Carriero's remark that "processes in a parallel program usually don't care what happens to their data." Since "receive" and "send" can be suspended until data or queue slots, respectively, are available, this routine works even though not all IPs are in storage at the same time. We now have a portable component which can compute the total weight of any stream of IPs for which "weight" is defined.
In addition, in OO, this function has to be a method contained in any collection class for which you might need to perform this function, whereas in FBP, once this function has been built, we can use it (just by referencing it in a network) on any data stream which conforms to certain conventions, without having to modify the definitions of any of the classes involved. As we said above, "a's weight" has to be defined for each IP in the stream. However, we can even parametrize the attribute name, so we can use the same object code to get a "total x" from all data streams for which "x" is defined. Instead of having a myriad small, special purpose, methods for every different class in the system, we arrive at robust, flexible, functions which are highly portable, e.g. (in this case) a function to determine the "total x" for any x which is defined for the IPs in the stream. In fact, we could even generalize this function still more: you could use a very similar structure to get the maximum or minimum weight of all the contained items. Of course, in this case "tare weight" would not be too relevant, but whether we are adding the contained item weights together or taking their maximum could also be provided as a parameter to our component.
To recast this function in OO terms, we would need to provide some kind of configurability. Assuming that we follow OO and make the "send" and "receive" functions "messages" to objects, then the objects "send" and "receive" talk to could actually belong to any of the following object types: other processes, streams, connections or ports. The only one of these which would not reduce the component's portability would be ports, unless the names of the other objects were passed in as parameters to the process. However, the latter alternative would clutter up the component's parameters with connection information. Port names would be the way a process identifies its "own" ports, and could be instantiated by a function very like THREADS's "define ports" service (see Appendix), which would accept port names and return an object handle. The "compute total weight" process logic can then send messages to its ports, to do receiving or sending, using normal OO syntax. We will of course need some kind of Driver or "connection" engine to connect our processes together using these ports together with a list of connections, to give us our desired configurable modularity, but this is outside the component logic.
The last thing we need to decide before we can recast our component in OO terms is how to determine the "x" of a given IP. There is no problem conceptually with making this a normal OO "message", as "get first" and "get next" will have returned a handle to an IP, which we can then send messages to. However, how should we name the function of obtaining "x" for the subject IP? Based on FBP experience, I suggest that the simplest technique is to have a generic "get" and "set" function which accepts the field name as a parameter (or even multiple field names to reduce the overhead). OO purists may feel that it is better to have multiple "get" and "set" methods - one of each per field - but this leads to a very large number of almost identical method subroutines.
Whether we implement attributes as OO methods or by using subroutines hung off the descriptor, we can do other things than just retrieve real data. We could also use these techniques to make sure related field values are kept in step (data integrity), or to support "virtual fields" (fields which are computed as they are needed). Thus a request for the number of children of Joe could scan Joe's attached IPs (where Joe is a "tree" structure) and return the result. The requester need not know whether the field is real or virtual. Such a mechanism would let the data designer either go for computation speed at the expense of having to maintain duplicate data, or, on the other hand, go for highly consistent data at some cost in performance. Another capability is what is sometimes referred to by the name "daemons": this involves the ability to automatically trigger events when a field value changes or passes some maximum or minimum. When combined with asynchronism, this could be a very powerful structuring tool for building business applications.
One important topic I want to address is the issue of granularity. All discussions of both OO and FBP eventually come up against this topic: how "big" should FBP processes and OO classes be? The lower end of FBP granularity is determined by the fact that IPs normally have multiple fields and often represent objects in the outside world. You could chop a business IP up into one IP per field, but then you would have to pay a lot of overhead to recombine it to write it on a file, data base, screen or report. The granularity of a language like C++ is approximately the same as that of FBP: objects very often correspond to file records. Many Smalltalk objects are at this level, but Smalltalk also makes much smaller pieces of data objects, such as amounts of money. Even integers are treated as objects, although the implementation for these is a little different for performance reasons. Smalltalk is able to be much more granular than FBP, but only because of its synchronous nature - "attribute objects" stay together because there is no tendency for them to drift apart in time. I believe the granularity of asynchronous systems will naturally tend to be coarser, unless counteracted by expensive (re)synchronization mechanisms.
As I talked to people about OO, however, I came to realize that there is one area which OO (Smalltalk anyway) does address which is absolutely unique to it, and in fact takes care of a problem which has been worrying me for several years: the need to be able to prevent illegal operations on data fields, e.g. to stop currency values from being multiplied together, or dates from being added (this was referred to as a problem above). However, this ability can only be taken advantage of if one does everything in OO, rather than combining it with existing HLL facilities. As we said before, the vast majority of HLLs are based on mathematical ideas of data, and treat numeric fields as dimensionless. They thus cannot provide intelligent handling of most of the numeric values one runs into in business applications - these are either dimensioned numeric quantities (like money or weight) or aren't even in the pure numeric domain (e.g. dates). In HLLs, all these types of data are compressed into a single numeric format which is indistinguishable from other numeric values. In Smalltalk all accesses to data values are via methods, so we are not forced to throw away our knowledge about what fields really represent. A "multiply" operation can be resolved to one or more methods which know how (or whether) to do the appropriate operation on the fields involved. Hybrid approaches lack this power, and any attempt to combine OO with conventional HLLs in the same process vitiates this checking ability. Some of the newer HLLs provide similar forms of checking, e.g. Ada, so a possible solution is to restrict the "business logic" parts of an application to using an OO language or one of these newer compilers.
If all of the above seems unduly negative, it is mainly that I feel a need to put OO into a proper perspective. OO is a simple technique, whose main importance is that it has started a sea-change in the way programmers think. It is definitely a step on the way, but my 20 years of experience with FBP tell me that, if we stop at this point, eventually frustration on the part of programmers is going to win out over the initial excitement. While I recognize that learning and using OO is an important learning experience, it is a hard way to learn, and, in its present form, an expensive way as well, as without configurable modularity the result will only be marginally more maintainable code. Configurable modularity can be added to OO, as can multithreading, just as they can be to conventional programming, and it is exactly the combination of these which starts to open up interesting possibilities.
In an FBP environment, it is possible and, I believe, highly desirable to mix processes running different languages, some OO and some non-OO. For instance, one process might be running a pure OO language, another one COBOL, another Assembler, and so on. Such a mixture would require that IP layouts become a public interface between processes, but note that this public interface should preferably be IPs associated with their descriptions. We now have a natural role for IP descriptors: to allow us to retain the IP attributes' domain information, which could be exploited by OO, across processes which do not use this information (e.g. ones written in existing HLLs). OO processes could in fact be protected by interface processes which turn IPs into some format acceptable to the OO language chosen. Such a combination of processes could even be packaged as a composite component, giving what seems to me to be the best of all worlds!
Wayne Stevens suggested a few years ago that objects might split very naturally into "process-like" and "data-like" objects, where, essentially, process-like objects would correspond to FBP processes, and data-like objects to IPs. In the phrasing I used above, data-like objects are passive, while process-like objects are active. Process-like (active) objects are able to act without necessarily always having to be triggered by an event external to them. In traditional OO systems, all objects are passive, and the whole assemblage is triggered by one (non-object) trigger that starts the whole thing running. This approach is obviously going to suffer from the same difficulties as traditional hierarchic non-FBP programs. If, instead, some of the set of objects can be active, we can start to capitalize on our experience with FBP. You will also notice that FBP processes have their own internal working storage, which looks very much like an OO object's "instance variables". Having process (active) objects and data (passive) objects looks like a very good way to combine the strengths of these two complementary technologies. In fact, with the appropriate infrastructure, different objects can be coded in different languages. Since, as we have shown above, one of the basic reuse mechanisms in FBP is the external definition of connections, we could also add a "driver" and "network" object: this would be an active object using the network definition as reference data.
My belief in the potential for combining the strengths of these two approaches is bolstered by the fact that, in FBP, we have actually built processes which behaved much like objects, and also by the observation that traditional OO applications often have objects that should really be separate processes. An example of the former is the List Manager which I described in Chapter 21. This component managed multiple lists arranged in levels. An example of the converse is a Data Base Manager object, which accepts requests to get, insert or delete data. As we have seen in earlier chapters, this is better implemented as an asynchronous process, rather than driven synchronously by other objects. Our List Manager suffered from the problem that it was very sensitive to the exact sequence of requests, which made it hard to use in a highly asynchronous environment. It would have been better implemented by externalizing the lists as FBP trees, so that one or more processes could work on these trees asynchronously. In other words, objects with overly complex internal data will be hard to use when we start to have more processes running in parallel. I expect this will apply even more noticeably as we start to distribute logic across multiple processors.
A number of writers in the OO field have started to explore the possibilities of active objects. In Chapter 1 of a collection of essays compiled by Kim and Lochovsky (1989), O. Nierstrasz makes the point that systems which mix active and passive objects would not be uniform, and this seems a valid point. However, one possible solution is offered by a system called Emerald (Black et al. 1986), which was designed for implementing highly distributed systems, and which maintains uniformity across all its objects by allowing every object to have a single process in addition to methods. Not all objects may activate their processes, but the potential exists for them to do so. This suggests a very workable generic structure for all the objects in a combined FBP/OO hybrid.
OO research and development seems to have entered a stage of accelerated growth, and it is very exciting to me that some of the newer work bears an uncanny resemblance to FBP! A dichotomy seems to be developing between the synchronous and asynchronous OO approaches, just like the one we have seen in non-OO. A number of OO researchers believe it is the asynchronous approaches which will turn out to have the most to contribute to the programming art in the long run. More and more of these people are discovering the power of active processes to broaden OO and make it better match the real world. Tsichritzis et al. (1987) have used the concept of active objects in knowledge processing - they call their objects KNOs (KNowledge Objects). KNOs can also have a complex structure, analogously to FBP composite components. Still more recently, Nierstrasz, Gibbs and Tsichritzis have collaborated on another paper on Component-Oriented Software Development (1992) which approaches FBP even more closely, but is still based solidly on traditional OO concepts. While their terminology is different from that of FBP, many close correspondences between the two can be established. They use the term "script" to mean "a set of software components with compatible input and output ports connected". While scripts can be data flow or object-oriented, the data flow version corresponds closely with FBP networks. "Scripting" means the construction of scripts, so the term "visual scripting" is defined as "the interactive construction of applications from prepackaged, plug-compatible software components by direct manipulation and graphical editing". In their article they talk about reusable components, ports, SACs (scripts as components) and visual scripting - all ideas that have direct counterparts in FBP. The same article goes on to describe an application of these concepts to multimedia called the "visual museum". "Media objects" (which are active objects, i.e. processes) work on "media values", which are
"...temporal sequences.... Media objects produce, consume and transform media values.... Media objects, in turn, are grouped into multimedia objects by specifying the flow of values from one object to another - we call this flow composition.... flow composition actually produces applications...".
Another remark in the same paper that I found interesting was,
"One benefit of flow-based composition is that new functionality can be added, or removed, by simple modifications to the script".
In the conclusion of their article they stress a number of the points I have made elsewhere in this book: the difficulty of generalizing to create good reusable components, and the economic and project planning impediments to producing such components. This equation of objects = processes seems to be gaining acceptance: the article describing A'UM (Yoshida and Chikayama 1988) matter-of-factly describes the system as consisting of "streams" and "objects" (for more on this interesting system see the next chapter). They then go on to say that of course streams can be objects also - which seems very close to what we were saying earlier about the possibility of treating IPs as objects.
From an FBP point of view, the concept which I feel is missing from traditional OO (not from the work on active objects) is the concept of "transformer" processes (many of the media objects described in the above-mentioned paper are explicit transformers). As Nan Shu (1985) has pointed out, much of business programming has to do with transforming data from one format to another. The paradigm of passing a stream of data packets through a transforming process seems to fit very naturally with this image, but this does not seem to fit well with traditional OO. Since the traditional OO paradigm specifies that only the methods of a class should know an object's internal state (which is presumably held in some canonical form), this would seem to imply that transformations are only of interest at the boundaries of an application (when one is bringing in or outputting "foreign" files, reports or screen data). In practice, as businesses build bridges between more and more of their applications, we will spend quite a lot of time converting data between different formats. Some of these applications will be vendor-provided, so the users will have even less control over their data formats. If these applications are OO, how will their classes be merged with the corresponding classes of the users? Data conversions will also be required for many of the common data transportation techniques - this will become more and more important as we move towards distributed systems. Thus, you might decide to convert binary data into character format to simplify transportation between PCs and hosts. Descriptor-driven transformers in an FBP environment will provide a simpler paradigm and will help to make all this run smoothly. Interestingly, in the paper I was talking about above, the authors also feel that multi-media applications will require a wide range of transformations of media values into different forms, depending on the various uses they need to be put to.
I found it significant that many of the media objects in the paper on Component-Oriented Software Development have names which are verbs, rather than nouns, e.g. render, interpret, provide (in FBP, processes are usually verbs, while IPs are nouns, e.g. customer, account, department). Traditional OO essentially works with nouns, with the verbs relegated to the methods - this has the effect that, for instance, to record the fact that a student has taken a course, you express this by having the student send messages to the course, or the course to the student. From an FBP viewpoint, it seems more natural to handle this with a process which transforms the student in well-defined ways. So an OO approach which is perhaps closer to FBP's way of thinking would be to send both student and course to a separate "attacher" object, which has the ability to associate students and courses. This object would be an active version of the general category of object called "dictionaries" in Smalltalk. These are two different, not necessarily incompatible, viewpoints.
It seems quite probable that powerful hybrid FBP/OO systems will be built within the next few years. Such a combination may well have some interesting and unexpected capabilities. Unfortunately, one problem the OO part of it is almost certain to have (until the new highly parallel hardwares appear on the market) is that of performance: for every field in every information packet accessed by an OO method, you need a call, plus logic to locate the method. In FBP, you can totally hide the layout of your IPs, and you can control your performance - accessing a field may be as little as one instruction, or it may be a complex function: it is your choice. Incidentally, the performance issue makes it doubly important to be able to select which part of an application is to be written in an OO language, and which in a conventional language.
The performance problem and the many arguments in favour of the asynchronous process approach to applications design lead me to believe that, if OO starts to be used for business production programming, it will be the concept of active objects (process objects) which will turn out to be more productive for OO than the original indirect call mechanism. To me active objects seem to be a natural evolution of OO in a direction which will eventually converge with FBP. If one can say that conventional OO (static objects) provide autonomy of data and autonomy of logic, then active objects also provide autonomy of control. Without the last, I believe it is not possible to build the systems we need in the future.
After I wrote the above, I came across the following comment by C. Ellis and S. Gibbs in Kim and Lochovsky (1989):
"In the future, as we move beyond object-oriented programming, it is likely that one of the useful enduring concepts is that of 'active objects'."
I agree absolutely! Over the next few years I believe that we will see more and more OO proponents talking about the advantages of active objects. I applaud this as it will expose FBP to a wider audience, but it may leave the programming public with the erroneous impression that FBP is a rather complex extension of the basic OO set of concepts. In reality, as I have shown in the foregoing pages, FBP can in fact be implemented with quite simple software and yet yield great gains in productivity, while OO can only do this if it incorporates advanced concepts which seem to be converging with FBP. To quote Ellis and Gibbs again on this matter:
"Although we foresee that object-oriented programming, as we know it today, is close to its deathbed, we foresee tremendous possibilities in the future of active object systems [my italics].... Vive l'objet actif."
The celebration may perhaps be premature, but, if you have read this far, you will have some idea why so many of us feel so excited about these concepts!
Before leaving this topic, I would like to make a last point which I consider vitally important: any evaluation of a programming technology must be done in the context of building and maintaining real business applications. There are only three reasons I am aware of for adopting a new technology: performance, productivity and maintainability. Even if a new technology allows us to get applications working faster or sooner, if it does not result in significant gains in maintainability, it may not be worth the effort. As I said earlier, we have to try out potential tools on the day-to-day concerns of business programmers, rather than on artificial, theoretical puzzles, no matter how intellectually stimulating they may be! When we have an OO application which processes every one of over 5,000,000 accounts 5 days a week at a bank, is easy to maintain and does not use prohibitive amounts of resources, we will truly be able to say that OO has come of age!