This chapter has been excerpted from the book "Flow-Based Programming: A New Approach to Application Development" (van Nostrand Reinhold, 1994), by J.Paul Morrison. A second edition (2010) is now available from CreateSpace eStore and Amazon.com. The 2nd edition is also available in e-book format from Kindle (Kindle format) and Lulu (epub format). To find out more about FBP, click on FBP.
For definitions of FBP terms, see Glossary.
|
Material from book starts here:
I cannot stress too strongly that FBP is intended for building real systems, and indeed the various dialects I have been describing in this book have been successfully used for this purpose many times! To achieve this, we have to keep performance in mind - not only must a system do what it is supposed to do, but it must do it in a "reasonable" amount of time. While admitting that this is a subjective measure, I submit that, at a given point in time, we generally have an image in our heads of what constitutes a reasonable amount of time for a particular function. While there will almost certainly be disagreements, say between users and developers, we see the use of SLAs (Service Level Agreements) becoming more and more widespread, which force the parties involved to reach some sort of compromise between what one wants and the other will commit to. Response time is another area which is highly subjective, but studies have shown that there are observable differences in behaviour as response time changes, which match the users' subjective impressions. Once people get used to subsecond response time, anything worse is highly frustrating. If it gets really bad, their whole style of interacting with the machine has to change.
Now a system which has to deliver function to real life users has to be reliable, and also has to perform. A system may provide wonderful function, but if you cannot produce adequately performing systems, it will only be of academic interest. Suppose you decide that you are going to interpret English descriptions of function using a natural language parser - it may be a great research project, but, given present-day (1993) technology, you probably can't run a bank on it! Can you "run a bank" on an FBP implementation? Yes, we've been using it for a large chunk of the batch processing of a bank's bread and butter transactions for the past 20 years!
Now, not only must the infrastructure be fairly fast, but it must be tunable. Key to this, I believe, is being able to form a mental model of what is going on, and where a performance or logic problem may be occurring. If a developer or debugger cannot do this, the reaction may be to want to throw the baby out with the bathwater. Adequate performance is important even when a new system is in the evaluation stage. At this point, overall impressions can be very important. The system has to have knobs and levers that let the developers tune the system, and the system has to behave in a linear manner. Linearity means that systems must "scale up". As you add function, not only should you not get sudden breaks in continuity - crashes, unexpected results - but ideally the curve should not even be exponential. In conventional programming environments typically complexity, and therefore development time, goes up exponentially as program size. Humans tend to have difficulty grasping the implications of exponential curves.
While it is possible that software could automatically balance two variables, I believe performance is a multiple variable problem. In any given application, a programmer has to juggle resources, algorithms and whole design approaches. Given this complexity, the software should be made as transparent as possible. In FBP, although there are many possible solutions to a problem, the developer can select a solution and then see the results, and can in fact iterate quickly through a large number of possible solutions.
In my experience, the single most important factor affecting performance is the design. In general, shaving a few microseconds off a subroutine will not make much difference, unless it is being performed billions of times. But a different approach to a design can often save seconds, minutes or even hours. Here is a simple example: about 20 years ago, a programmer on a project I was on needed to calculate the day of the week, given a date. He decided he would need a data base, running 3 years into the future and 3 years into the past. Of course the data base would have to be maintained by hand, so he planned for it to be updated once a year. Even without taking into account the manual labour and the difficulty if he was presented with a date outside the data base's range, I just figured that it might be a lot simpler to calculate it mathematically! Eventually this huge effort turned into a macro of about 12 statements - guaranteed until the year 2099! I am sure you are saying that's a trivial example and that we were all ignorant, but I am sure there are examples in your code where a small change of viewpoint can yield a big dividend in performance or maintainability, or both!
However, to be able to take advantage of these changes of viewpoint, you have to have a modular system. With FBP, as we saw elsewhere in this book, you can replace a sort by a table look-up, or a file by a connection; you can move function from one job step to another, or from one system to another, and so on. As the programmer I quoted earlier told me, "One of the things I like about AMPS is that there are so many more ways to do a job than with conventional programming". There is never just one way to do a job. And an FBP developer is continually making conscious trade-offs between different factors. For instance, she might decide to favour response time over throughput, so that might tilt the scales towards direct access instead of sorting. Or the old storage vs. CPU time debate. Or within a component, you can trade off state data against code: Boolean switches can either be held in a variable, or can be implemented by choosing between two code paths. It is important to know what options are available to you, and the system must allow you to choose the one you want.
The fundamental trade-off we make in FBP is that we have decided to spend a certain amount of CPU time to get improved programmer productivity and program maintainability. Of course the industry has been doing this since HLLs and operating systems were invented, so this is nothing new, but you always have to decide how much you are willing to pay. But the amount also has to be controllable - a certain cost may be appropriate for one type of application, but wildly inappropriate for another.
In the case of FBP, the cost is closely related to the number of processes, which in turn is related to what is called "granularity". In general, the finer the granularity, the more CPU time gets used, so you can afford smaller "grains" in an infrequently used part of our application network. Conversely, 5,000,000 IPs going through a path of 12 processes will cost at least 120,000,000t units of CPU time, where 't' is the cost in CPU time of one API call (each process is going to cost at least 2t units per IP - for a receive and send). Depending on the speed of your machine and what 't' is, you may decide that 12 is too many. Reducing this number will probably entail some sacrifice in terms of reuse or modularity, as you will be combining smaller, reusable functions into larger, more ad hoc components.
Periodically, people will write an FBP network and a PL/I program which do the same thing and then compare their performance. This is really comparing chalk and cheese! The maintainability of the two programs is totally different, as a PL/I program adds far more maintenance load to your DP department than does an FBP network. Furthermore, if a bug in a generalized component is fixed, everyone benefits, while if a PL/I program bug is fixed, usually there is no lap-over to other applications.
Susan came to us with a program which she felt was slow compared with a "reasonable" execution time. I noticed that she was using the Assign component to set a 1-byte field in every IP, and there were a lot of IPs. She had been told to make her program very modular, but also she probably felt that Assign was a neat function, and it meant that much less PL/I that had to be written and maintained. I suggested that she add a single statement to each of a couple of her hand-coded PL/I components. There were other things we could do which together improved the running time significantly. Although we "improved" her program to the point where its performance was acceptable, we probably reduced its maintainability slightly. But this is another trade-off for which no general rules can be given - each situation has to be decided on its own merits. I mention this example mainly to stress that it's a complex decision whether to use a separate generalized component or add function to custom components, involving issues of maintainability, performance, predicted use, ROI and so on. There is a strong element of the aesthetic here - nobody should make the decision for you, just as nobody can tell you which paintings to like. Maybe someone will, but that's life!
The bottom line is that we have to give application designers as many choices as possible, and as much control as possible, and systems which won't or can't do this won't survive. Why has COBOL survived when so many more sophisticated products have fallen by the wayside? Because, even if you don't like it aesthetically, COBOL does provide this control, even if it takes years to write a system and, once written, it's even harder to maintain. However, COBOL systems degenerate over time, as the developers lose knowledge of, and control over, what's going on under the covers; FBP systems don't.
Now let's talk about specific techniques for tuning the performance of FBP applications.
IN Chapter 20, we talked about the basic MVS synchronization technique of WAIT on ECB. We found that quite often when the same program was written in, say, PL/I and in DFDM, that the elapsed time of the DFDM run would be less than that of the PL/I run, but the CPU time would be somewhat greater. It becomes obvious why this should be so if you visualize an FBP network with 6 processes all doing I/O: provided the I/O is using different channels, drives, etc., it can all be happening concurrently, while the scheduler will always be "trying" to find CPU work to do to fill available CPU time. FBP programs tend to be CPU gluttons, but that is also the designer's choice - if he or she is concerned about this, I/O processes can be prevented from overlapping by synchronization signals. Usually, however, programmers want to reduce elapsed time, e.g. to fit into a processing "window" (time-slot). Today windows are getting shorter and shorter, so there is pressure to reduce elapsed time, even at the cost of more CPU time.
As we described above, using FBP connections in place of intermediate files definitely saves elapsed time, as all the records no longer have to be written out to disk and read back in again, but it will save CPU time as well, due to the reduction in the number of EXCPs (EXecute Channel Program). In MVS, although the EXCP count is maintained as a separate piece of statistical information, people tend to forget that EXCPs are quite expensive in terms of CPU as well.
Here are some statistics recorded during an evaluation of DFDM
against
an existing PL/I application, done by an IBM I/S site in the US:
I/O EXCP requests: 53.6% reductionHere is what they said about those figures:
CPU Usage: 16.7% increase
Elapsed execution time: 37.7% reduction
External DASD requirements: 84% reduction
"We attribute the above reductions in resource usage to the improved design of the application (as a result of using structured analysis which is promoted in conjunction with DFDM). The slight increase in CPU usage is a small trade-off when you take into consideration the improved design of the application which should significantly lower future maintenance."
Let's say that you have tuned your I/O as well as possible, and that you are now trying to estimate how much CPU time your application will take. I have found that the main predictor for CPU time is the number of API calls. On the IBM Model 168 (this was about a 2 MIPS machine), each API call took approximately 10 microseconds. Of course later machines are much faster, but later implementations of FBP are typically written in higher level languages, have more features and do more checking, so the time has probably stayed approximately constant. Just for comparison, I recently did some measurements on THREADS, running on a 33 MHz 80486DX, and the time per API call was approximately 50 microseconds (THREADS is written in C, so this figure could probably be improved by rewriting critical sections of the scheduler in Assembler).
Now, in most networks, there is usually a "back-bone": a path where most of the IPs travel. You could think of this back-bone as much like a critical path in a Critical Path Network. Let us suppose that this path consists of 12 processes, each sending and receiving: then, taking the figure of 10 microseconds, we get a cost of 240 microseconds per IP. If 5 million IPs travel this path, you get a total CPU time for API calls alone of 1,200 seconds, or 20 minutes. You may therefore decide that you want to consolidate some of the number of processes in the application "back-bone" into larger, less generalized ones - as we said above, this will reduce maintainability, but you may well decide that it is worth the price. Of course, you don't have to consolidate all the processes in your network - areas of the network which are visited less frequently, like error handling logic, may be left more granular.
It is common wisdom nowadays to concentrate on developing function first, and then worry about performance afterwards. This is quite valid as long as you don't squander performance up front by poor design. And here of course is where aesthetics comes in - I started my programming career on an IBM 650, which had 2000 10-digit words stored on a spinning magnetic drum, and I believe that it became almost an instinct to make programs as lean in terms of time and storage as possible. But, even in those far-off days, there was wide variation in the performance of code by different programmers. I believe the most successful ones never lose sight of the performance requirement, so that it is a constant undertone to their program designs. If you ignore performance and expect to add it back in later, you will generally be disappointed in the results!
Having said that, I must also warn against the other extreme - Wayne Stevens repeatedly stressed that you will generally not be able to predict where is the best place in your application for you to focus your tuning efforts. You may spend lots of time trimming a few seconds off some code which turns out only to be used occasionally. It is much better to run a performance tool on your application, using representative data, and find out where you should really be putting tuning effort. You can actually use the time you have saved by using an improved methodology to tune the parts of your system which make a real difference. One of the satisfying things about FBP is that, once you have improved the performance of a component, all future users of that component will benefit.
Similarly, you may decide to create a variant of a component to exploit a trade-off, and again you have increased the range of choices for future users. An example of this is a coroutine I built 20 years ago to read disk files faster than the standard reader, but at the cost of more storage. We had a large BDAM data set which had to be read as fast as possible. The regular sequential reader worked fine, as this data set could just be treated as a sequential data set (in MVS BDAM and BSAM files are held on disk in essentially the same format), but I also knew that all the records of a BDAM data set were the same length, which is not necessarily true for sequential files. Now the tracks of an IBM disk drive start at a point called the index point, so, to read a track, the access method has to wait until the index point comes around before starting to read the data (this is called "latency"). If you miss it, you have to wait a full revolution for it to come round again (and we could see this happening in our performance studies). I also knew that each record is physically labelled with a record number on the track, so I figured that it should be possible to start reading anywhere on the track, and just determine the record sequence afterward. Since this technique would be imbedded in an FBP component, it could still generate the records in the correct sequence. You do have to calculate the number of records per track first, but all the records are the same length, so there are standard formulae and tools for doing this. On the minus side is the fact that this approach takes up a track's worth of storage, and your code is somewhat tied to the device's characteristics; on the plus side, it's fast! In our case, this Read Track component was definitely worth it - it didn't get used widely, but, when we needed it, there was nothing like it! Remember also that in FBP there is never just one way to do a job, so nobody is forced to use your component. This component can just be added to the tools available for your programmers to use - they just have to understand its behaviour, not how it works inside. By the way, training programmers to think like users is not that easy! [This example has apparently been obsoleted by new hardware design of DASD, but I still think it's a valid example of a certain type of thinking, so I have left it in the text.]
Another kind of trade-off can be made in FBP by varying the capacity of connections. FBP's connections provide a powerful way of trading off CPU time against storage. All FBP schedulers so far have followed the strategy of having a process continue running as long as possible, until it is suspended for some reason. Now the more IPs there are in a process's input connection(s), the longer that process can go on before a context switch has to take place (assuming there is room in its output connections to receive the output). So, in general, larger capacity connections reduce context switches, and therefore CPU time. But, of course, larger capacities mean more IPs can be in flight at any point in time, so your application will take up more storage. Another way of looking at this is that you are effectively loosening the coupling between processes, so larger capacity connections equals looser coupling, whereas smaller capacity connections equals tighter coupling. For instance, we discovered that sequential readers perform best if their output connections can hold at least a block's worth of records.
The Read Track coroutine described above was used in conjunction with some other techniques to reduce a disk file scanning job from 2 hours to 18 minutes. The original running time of 2 hours was a cause for concern as we knew that the data we would eventually have to process was several times the amount we were using in the 2-hour run. It therefore became imperative to see what we could do to reduce the running time of the job. We achieved this significant reduction by changing the shape of the network and adding one new component. This example used AMPS and is described in my Systems Journal article (Morrison 1978), but for those of you who may not have access to it I think it's worth repeating here, as it embodies some very important principles.
The application scanned chains of records running across many disk packs. One set of packs contained the "roots" of the chains, while another set of disk packs contained what we might call "chain records". Each root contained pointers to zero or more chain records, which in turn might contain pointers to other chain records, which could be spread over multiple packs. The problem was that our insert and delete code was occasionally breaking chains, so I was given the job of running through every chain looking for broken links - but obviously the scanning program could not use the same code that was causing the problem! So I had to write all new programs to do the scanning job. These programs understood our pointer structure, and there was enough internal evidence that I could always detect a broken chain.
My first approach looked like this:
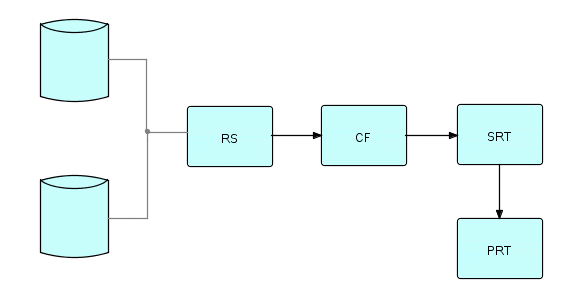
Figure 22.1
where RS means Read Sequential. This was the standard reader - we just concatenated its input files together, so its disk packs were read one after another. CF was the Chain Follower which follows chains from one record to the next and outputs diagnostic information only when it finds a broken chain. SRT sorts the output of CF to put it into a sequence which is useful for humans, and PRT prints the results of the Sort process.
The reason for the Sort is that the root records were scattered randomly on the root disks, whereas it was more useful to see the errors ordered by, say, account number within error type. Since the number of errors should gradually diminish to zero as program bugs in the access methods were fixed, the overhead of the Sort process would diminish over time also.
This program as shown above took 2 hours to run, even though we were using a test data base, so we absolutely had to speed it up!
My first realization was that the CF component was heavily I/O-bound, as it was spending most of its running time doing direct accesses to disk records, which usually included a seek, disk latency and then a read of a record into storage. I figured that, if we could run a large number of these processes concurrently, the I/O times of the different processes would tend to overlap. However, if we had too many parallel processes, they would start contending for resources, i.e. channels and arms. I therefore decided rather arbitrarily to have 18 of them running concurrently.
I also thought that, since the roots were scattered across multiple packs, we might as well assign each pack its own reader and let them run in parallel also. And, if I was going to do that, why not use the full track reader I described earlier in this chapter? Its output is data records, in the right order (although this wasn't even strictly necessary for this application), so the next process downstream wouldn't see any difference.
Lastly, I needed something to tie together these two kinds of process: I needed a process which would assign incoming root IPs to one of the CF processes, in a balanced manner. I could have just done this using a round-robin technique, but I wanted to try something a little "smarter": could I select the CF process which had the least work to do, and thus keep the load across all the CF processes in balance? I reasoned that the most lightly loaded process should have the smallest build-up in its input connection, so if I always sent a root IP to the CF process with the fewest IPs in its input connection, this would have the desired effect. I therefore wrote a load-balancing component which checked its output connections looking for the one with the smallest number of IPs. I feel this approach is quite general and could be used in many multi-server situations.
Here is a picture of the final structure:
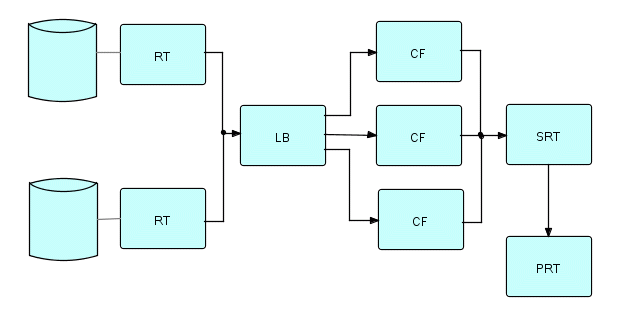
where RT is the full track reader. LB is the Load Balancing coroutine, and the
other processes are as before.
Figure 22.2
- Final result: elapsed time down from 2 hours to 18 minutes.
- Programming cost: one new generalized component (LB) and a change to the network. We might want to count RT, depending on whether we feel this was written for this purpose, or independently of it (it sort of happened along at the right time!). Furthermore, all these generalized components can be used in future applications.
The FBP diagramming tool, DrawFBP, supports the multiplexing
function shown above using a simpler notation, which also lets the
designer fill in the multiplexing factor - this is the result:
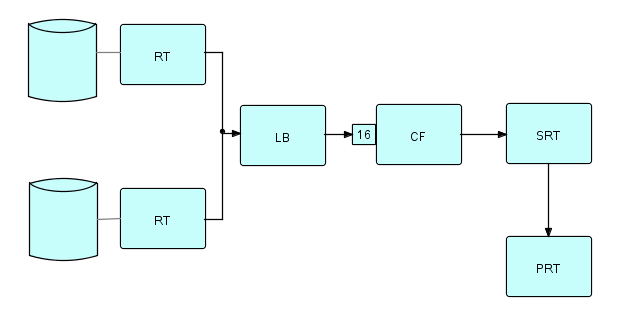
Figure 22.3
You may have been wondering how a component can check how many IPs are in a downstream connection when we have never mentioned a service to do this. This is an area of technology which I'm afraid is not "pure", but which I suspect comes up often when a concept has to come down out of its ivory tower into the world of real applications... We never did build an encapsulated service to count the IPs in a downstream connection and, if we had, it probably would have had to be a lot more complex. Instead we allowed one special component to peer into the insides of the infrastructure, so it effectively became an extension of the scheduler. I understood that it would have to change any time the internal structure of the scheduler changed, but that seemed better than providing a new service for the benefit of just one user. In hindsight it might have been even better to package the whole component as part of the scheduler, since then it would automatically participate in any changes made to the scheduler.
In DFDM, we had a very similar situation with the Subnet Manager, which also did strange things to the innards of the scheduler (you will remember that it can "revive" dead processes). DFDM's Time coroutine is a little bit like that too - this coroutine uses an existing, but unpublished, service to generate "clock tick" IPs, and is the only coroutine which is allowed to use this service.
Since I promised to talk about things which were not unalloyed success stories, I should mention DFDM's NIP (Next Input Port) service. This is a service which we were enthusiastic about at first, but we later felt less excited about. Also, new people will always be joining projects, bringing different experience and tastes. In fact we did not include it in the Japanese version of DFDM. It is also appropriate to mention it in a chapter on performance, as it was intended as a performance tool. The idea was to be able to monitor which input port data had arrived at, and signal this fact to the component, which could then do a receive from that port. If no data was waiting at any input port, the component code could specify that NIP was to suspend until some data arrived, or that you didn't want to suspend. The latter option provided a way of polling (which I think should be avoided anyway); the former option is much the same as tagging all incoming IPs to indicate their source, and then merging them into a single input port on a first come, first served basis. So all NIP really saved us was the need to allocate a field in each IP to indicate the source number and the need to set it. Perhaps its main appeal was that it matched very closely one's mental model of how a server servicing requests from multiple sources should work - but, as we have said above, this can be handled very nicely, just using FBP's many-to-one connection facility, so you really don't need to provide a separate service to do this.
I mention these situations to describe a type of problem which will certainly come up from time to time. Under the pressures of deadlines, performance requirements or just because you get a neat idea, you will either be tempted to introduce small breaches in the bastions surrounding your system, or you will be persuaded to put in complex facilities for one or two users. Conversely, you may put your foot down and refuse to give in, and lose some customers. Should you give in to these temptations, or should you stick to your guns because you know the possible pitfalls if you don't? I can't answer that for you - all I can recommend is that you try to make sure you have thought through all the pros and cons before you make your decision! One hint: good code (no, make that any code) lasts a lot longer than you would ever expect and, when some dialect of FBP (hopefully) becomes more widely used, it will last longer still. Will you still be proud of your code 20 years from now? I sincerely hope so, because there's a good chance you'll meet it again! And, no, customers are not always right, but they are not always wrong either!