Flow-Based Programming - Chap. XXV
Streams and Recursive Function Definitions
|
This chapter has been excerpted from the book "Flow-Based
Programming: A New Approach to Application Development" (van
Nostrand Reinhold,
1994), by J.Paul Morrison.
To find out more about FBP, click on FBP
. This will also tell you how to order a copy.

For definitions of FBP terms, see Glossary
|
[References to TR1 in the text refer to an application
component which is used in examples earlier in the book - see Chapter 10. TR1 "extends" detail records by
multiplying a quantity in a detail record by a unit price obtained from
a master record in another file. Processes "up-stream" of TR1 have
merged masters and details, so TR1 is fed a single merged stream
containing masters and details, and with related records delimited by
special IPs called "brackets".
Collate refers to a general, "black box", reusable component
that merges 2 or more streams on the basis of parameters describing the
location of control fields in its incoming IPs, and optionally inserts
grouping IPs called "brackets" into its output stream. It is described
in some detail in Chapter 8.]
Material from book starts here:
It is easy to see that an FBP component can be regarded as a
function transforming
its input stream into its output stream. These functions can then be
combined
to make complex expressions just as, say, addition, multiplication,
etc.
can be combined in an algebraic expression. A number of languages have
used
this as a base for notations. Let me take a simple example:
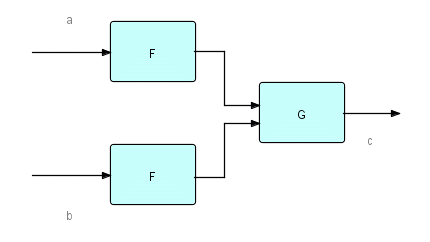
Figure 25.1
If we label streams as shown with lower case letters, then the
above diagram can be represented succinctly as follows:
c = G(F(a),F(b))
I deliberately used F twice to underline the fact that the
same function can be used many times in the same expression. Of course,
this relies on the function having no side effects - this is one of the
desirable characteristics of functional languages (and one of the
qualities which are desirable when designing FBP components). We will
return to this point later on.
Now we have seen that streams are made up of patterns of IPs, which
in turn have fields or data items. Is it possible to carry functional
notation to the point where we can actually build systems processing
real data? I believe it is, but in a way that will not be as
"mathematical" as most treatments of recursive programming. In the rest
of this chapter, I will develop the concepts of recursive stream
definitions. But first, for those of you whose math is a bit rusty, we
should talk about what exactly are recursive definitions. The rest of
you can skip ahead!
Recursive techniques are often taught using the formula for
factorials as an example. A factorial is the product of all the
integers greater than zero up to and including the number whose
factorial you want to calculate. Factorials can be (and often are)
calculated iteratively. i.e.
factorial(x):
a = 1
do varying y from x to 1 by -1
a = a * y
enddo
return a
Now, the classic expression for calculating factorials really does
the same thing, but it does it recursively, as follows:
factorial(x):
if x = 1
return 1
else
return x * factorial (x - 1)
endif
Here we see that "factorial" is actually defined in terms of
itself, but used on a "smaller" part of the problem. Since we use
factorial on x-1 , and the first test is always to see if we
have reached 1, we are actually getting one step closer to our goal
each time around the definition. If you
want to visualize how this might execute, think of a stack holding the
environment
for each invocation of factorial. Each time we start a factorial
calculation,
we push the information we will need onto the stack, so the stack gets
deeper
and deeper. When we eventually get a true condition on the first test,
we
can calculate a factorial (1) without pushing a new environment on the
stack.
Now we can finish all the factorial calculations (in reverse sequence),
so
that eventually we arrive back at the top of the stack and we're
finished.
Speakers of German will be familiar with a similar phenomenon which
occurs
in that language, where several "contexts" may be "stored" until the
end
of the sentence, at which time each context is terminated with the
production
of an infinitive or past participle.
The advantage of the recursive definition is that it has no local
storage variables. We therefore suspect that this characteristic may
have a bearing on some of the problems we identified earlier in this
book with the "pigeon-hole" concept of storage. Functions also ideally
have no side-effects, so they can easily be reused. If we combine these
concepts with some other concepts which have appeared in the
literature, we can actually describe (a small piece
of) business processing in a way which is free from a number of the
problems
which bedevil the more conventional approaches. I also believe that if
you
look back at Chapter 18, you will find that there are similarities
between
that notation and what will be pursued more rigorously in this chapter.
Admittedly
this will be a tiny example, but my hope is that someone will be
sufficiently
intrigued that they will carry it further.
Recursive functions are attractive to mathematicians because they
have no side-effects, and therefore are easier to analyze and
understand. In W.B.
Ackerman's paper (1979) he states: "the language properties that a data
flow
computer requires are beneficial in their own right, and are very
similar to some of the properties that are known to facilitate
understandable and maintainable software, ...." Some of these
beneficial properties are as follows:
Ackerman defines an applicative language as one which does all of
its
processing by means of operators applied to values. The earliest known
applicative language was LISP.
By now you should be familiar with the use of the term "stream" in
FBP to describe the set of IPs passing across a particular connection.
The stream does not all exist at the same time, but is continuously
being generated at one end and consumed at the other. However, it has a
"real" existence, and it can be manipulated in various ways. W.H. Burge
(1975) showed how stream expressions can be developed using a
recursive, applicative style of programming. D.P. Friedman and D.S.
Wise contributed a number of papers relating applicative programming to
streams by adding the concept of "lazy evaluation" (1976)
to Burge's work. This style has the desired freedom from side effects
and
has another useful characteristic: the equals sign is really a
definition statement, and can be used for proving the validity of
programs as well
as for doing the actual data processing. Such a language is called
"definitional".
Quoting W.B. Ackerman (1979) again: "Such languages are well suited
to program verification because the assertions one makes in proving
correctness are exactly the same as the definitions appearing in the
program itself." One can put a restriction on assignment
statements to the effect that the definition should not assign a value
to a given symbol more than once in a single scope. Thus a statement
like
J:=J+1
is ruled out because "J" would have to be given an initial value
within the scope, resulting in two assignments within that scope.
Also, viewed as a definition, it is obviously a contradiction! A
number of writers on programming have described their feelings of shock
on their first encounter with this kind of statement, only to become so
used to it over the years
that they eventually don't notice anything strange about it!
We shall now talk a little bit about the possibility of writing
programs in a way that avoids the problem of rebinding variables within
a scope, following
(Burge 1975) and (Friedman and Wise 1976) in the area of stream
functions.
Typically, like the definition of factorial shown above, the desired
output is defined in terms of two functions:
-
a function of the first item in the stream
-
a function relating this item to the rest of the stream
-
and a termination rule specifying a value to be returned when
the function bottoms out.
The following example resembles the definition of factorial shown
above, but moves closer to business applications. Even though it may
not much resemble the type of business applications that you are
accustomed to, you will have to admit that it is very compact! Suppose
we want to count all the IPs in a stream. Then, analogously to the
factorial calculation above, we could
write a "counter" function F as follows:
F(S) = if S is null,
then 0,
else 1 + F(rest(S))
where the result is specified directly by a value, e.g. 0, or 1
+ F(rest(S)).
With respect to the rest of this notation, functions are expressed
using the conventional bracket notation, and sublists will be specified
by means of curly braces. For instance, {w,x,y,z} is a sublist
consisting of
w, x, y and z. null tests for a
stream with no IPs in it, i.e. {}; first(S) is the first IP of
a stream, i.e. w in the above example, and rest(S) is a
list comprising all the rest of the IPs in the stream, i.e. {x,y,z}.
Notice that, while
rest returns a list, first only returns a single IP.
In this first example, F is called recursively to return a
value based on processing a stream S. At each invocation of F,
its environment (the part of the stream that it can see) is pushed down
on a
run-time stack. When an invocation of F finds itself looking at
an
empty stream, the null test returns true, F bottoms out, and
the stacked
environments are progressively popped up, until the original one is
reached,
at which point the process stops. Notice that there is a family
resemblance
between recursive definitions which only "recurse" at the righthand
end,
and right linear grammars (described in the previous chapter). This
kind
of recursive definition can also have special processing applied to it
which
maintains the stack at a constant depth.
Now so far we haven't actually used the data in the stream IPs.
Suppose therefore that we want to sum all the quantity fields in a
stream of IPs. We will introduce the convention a:x to mean
"field a of x". This notation and the "mini-constructor" notation
described below are based on the Vienna Definition Language, developed
some years ago by the IBM Laboratory in Vienna. The desired calculation
can now be expressed recursively as follows:
F(S) = if S is null,
then 0,
else q:first(S) + F(rest(S))
where q is the quantity field of an IP.
So far, we have only generated a single quantity from our stream. To
do anything more complicated, we will need to be able to generate IPs
and string them into streams. To do the former, we will need something
which can build an IP given a set of values for its fields. We will use
a special function for this which I will call the "mini-constructor" (µ).
This takes as its argument a list of selector symbols and values,
and returns as a result an IP with those values inserted into the
fields designated by the selectors. A selector and its value are
separated by commas, while selector/value pairs are separated by
semi-colons. The mini-constructor is
a concise way of specifying how new IPs are to be built.
To combine IPs into a stream, we use a variant of the well-known
list-processing function cons, which was first used in
functional languages to join two lists together. The following
equivalence holds:
a = cons(first(a),rest(a))
Friedman and Wise (1976) have extended this concept by removing the
requirement that both of the arguments of cons be available at
the same instant of time. Their "lazy cons" function does not actually
build a stream until both of its arguments are realized - before that
it simply records a "promise" to do this. This allows us to imagine a
stream being dynamically realized from the front, but with an
unrealized back end. The end of the stream stays unrealized until the
very end of the process, while the beginning is an
ever-lengthening sequence of items.
Suppose we want to create a stream of extended details (where the
quantity field has been extended by the unit price for the product): if
the unit price
were repeated in every IP, there would be no problem, as all the
information that a particular call to the function requires is
immediately available. Assigning selectors p, s, d,
q, u, e to product number, salesman number,
district number, quantity, unit price and extended price, respectively,
we would then be able to define
the extended details stream as follows:
F(S) = if S is null,
then null
else cons (E(first(S)), F(rest(S)))
E(x) = µ(p,p:x; s,s:x; d,d:x; u,u:x; e,q:x*u:x)
where E is a function which creates a single IP. The
expression after the last semi-colon in the definition of E(x)
would read in English:
"set the extended price field of this IP to unit price multiplied by
quantity".
This would be fine except for the fact that unfortunately the unit
price
is not in the same IP as quantity!
In fact, in the case of the merged stream being processed by TR1,
the unit
price for a given product is held in only one IP per substream - namely
the
master IP for that product. We could define a function "PM" ("previous
master"),
but that would violate the rule that a function can only "see" an IP
optionally
followed by its successors. Instead, let us broaden the concept
of
first and rest to work with lists of lists (just as LISP
and
the other functional languages do).
This concept of lists of lists allows us in turn to take advantage
of the
fact that a stream can automatically be structured into substreams by a
Collate
type of component. Thus, suppose the output of a Collate run is as
follows:
((m1,d11,d12),(m2,d21),(m3,d31,d32,d33))
where brackets represent bracket IPs. Then to convert this
logically into a structure of lists and sublists, merely replace the
open and close bracket IPs with curly brackets, i.e.
S:= {{m1,d11,d12},{m2,d21},{m3,d31,d32,d33}}
Now first and rest at the list level will return
sublists, i.e.
first(S):= {m1,d11,d12}
and
rest(S):= {{m2,d21},{m3,d31,d32,d33}}
Note that, analogously to what we saw above with simple lists, first
reduces the "nesting level" of a list by one level, while rest
leaves it unchanged. The processing for extended details can now be
shown
succinctly as follows:
F(S) = if S is null,
then null
else cons(G(first(S)), F(rest(S)))
G(x) = G'(first(x),rest(x))
G'(x,y) = if y is null,
then null
else cons (E(x,first(y)), G'(x,rest(y)))
E(x,y) = µ(p,p:y; s,s:y; d,d:y; e,q:y*u:x)
Here the one-argument function G is defined in terms of a
two-argument function G', whose first argument is always a
master IP, and E now takes two arguments instead of only one.
In the above it can be seen that we will generate one output IP for
each incoming detail (all IPs within a lowest level substream are
details except the first one, which is the master). We can also see
that x in G' acts as a place-holder for the master IP
- it remains unchanged
throughout the whole evaluation of function G.
Now let's repeat the three tables from Chapter 18 which describe the
same calculation, and you will see that essentially the same
information is captured, without the use of recursion, but also without
using any variables. It seems therefore that these tables must have an
underlying relationship with the functional expressions shown above.
The three tables from Chapter 18 respectively describe
-
the relationships between input and output streams:
INPUT STREAM
1. Merged Input
2. Product Substream: REPEATING
3. Product Master
3. Sales Detail: REPEATING
OUTPUT STREAMS
1. New Masters
2. Product Master: ONE PER Product Substream
1. Sort Input
2. Extended Detail: [ONE PER Sales Detail]
1. Report-1
2. Product Summary: ONE PER Product Substream [,NEW]
-
the layout of the individual IPs, e.g.:
Extended Detail:
{
Product Number: Ident,
Salesman Number: Ident,
District Number: Ident,
Quantity: Quantity,
Unit Price: MPrice,
Extended Price: Monetary;
}
-
and the derivation rules for computed values:

Although we have been able to show some of these calculations in
recursive form above, it appears that, in
this particular case, the same information content can be expressed
almost as succinctly using a quite simple notation which does not
require any mathematical expertise at all. We have alluded above to the
need to minimize the gap between the business requirement and the means
of expressing it. What is the absolutely most
concise way of expressing the requirement "build a stream of IPs
containing
extended quantities calculated as follows: ..." to a machine? In a 1990
article, K. Kahn and V. Saraswat suggest that it may not even have to
be
text as we know it - they propose that it may be possible to express
both
definitions and execution using a visual notation with almost no text
at
all, except for strings and comments. They point out that a major use
of
names is to make connections, something they are not particularly well
suited
for! Now look at the above figures and try to imagine how you could
replace
all those names by arrows connecting various types of icons (as few as
possible
of course).
Part of my motivation in this chapter (and in this book as a whole)
is to try to shake up some preconceptions about how programming has to
be done! We cannot predict where the next break-through will be made,
so it is important that we remain as open as possible to new ideas and
new ways of doing things. The above concepts also suggest some
desirable characteristics that these new ways should have, so we can
measure whether we are moving in the right direction or away from it.
As I shall suggest in the last chapter of this book, everyone should
have their minds stretched regularly, and this kind of exercise is
nowhere more important than in the computer business!